By storing the data across more than one table, you remove redundancy. Tables are linked by the use of keys, a primary key on the one side links to a foreign key on the many side. The first rule of database design is make primary keys meaningless. Ninety-nine times out of a hundred you will want to make a primary key an integer that increments by one for each row added to the table. Most databases even have an auto increment integer type or a sequence generator (that accomplishes the same thing) for just this reason. A sequence generator can be more flexible to use than the auto increment type, more on that later on.
So let's jump into the deep end and think about the design of our horse racing database.
First up, consider what is the purpose of the database. We want to be able to analyse racing history, and we want to be able to look at it from different angles - comparing individual horses in a race, comparing groups of horses (to get par times for example), comparing jockeys, trainers, tracks. We might want to be able to create our own ratings, be they class/weight à la Don Scott, time based, or purely statistical.
At a bare minimum, your database is going to need the following -
The date, start time, race no., track, distance, class and restrictions, prize money, going, and runtime of each race. The tab number, horse name, barrier, allocated weight, jockey, apprentice allowance, finish position, losing margin, and starting price of each horse in each race.
If we consider these as the columns of a single table, it would look like this:
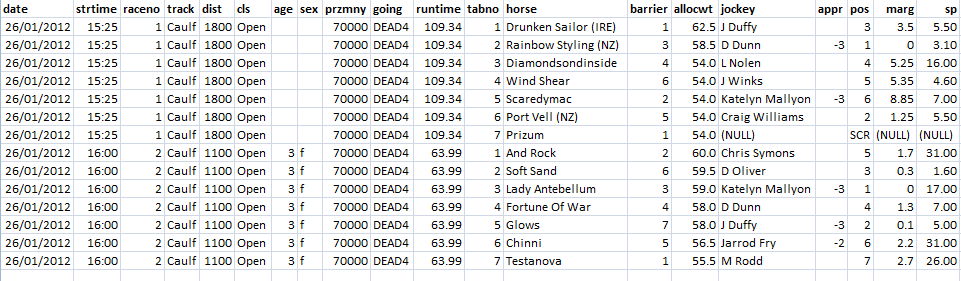
This clearly shows that data redundancy will occur unless this data is split across more than one table.
The next post will explain how to do this. The process has a name too, it is called normalisation.
Cheers